测试
奥力给!!!

在以往的系统中,我们都可以通过我们的命令行cmd来写我们的汇编的程序,而在win10的环境下,则需要下一个软件DOSBox 0.74-2,然后通过这个软件在进行我们的汇编编程。以下是该软件具体安装与使用:
1 | 1、使用debug,将下面程序段写入内存,逐条执行,根据指令执行后的实际情况填空。 |
开始没有认真的审题,所以开始我是把程序是写在了一个记事本,但我建议大家还是先下一个Notepad++的一个记事本,通过他来写我们的汇编代码,因为他会有明确的行数,在我们出现errror的时候,我们就可以更快的找到错误。
当然写在asm文件的程序之前,需要我们有安装步骤中的四个exe文件,不然无法使用,对于我们的文件需要我们先masm 【我们的文件】.asm ,进行一个编译,如果你的代码没有错误,则service error 和warning error 应该都为0,之后我们就可以link我们的成功的文件:link 【我们的文件】.obj;记住是obj,不要忘记了。其中问你是不是创建obj,exe什么的直接回车就行了。
如何运行我们的程序呢?之后直接我们的【我们的文件】.exe就行了。
a指令 debug之后输入的编译指令,输入我们的代码就行,之后你不想输入时,直接两次回车,我们就可以 输入我们的其他机器指令了
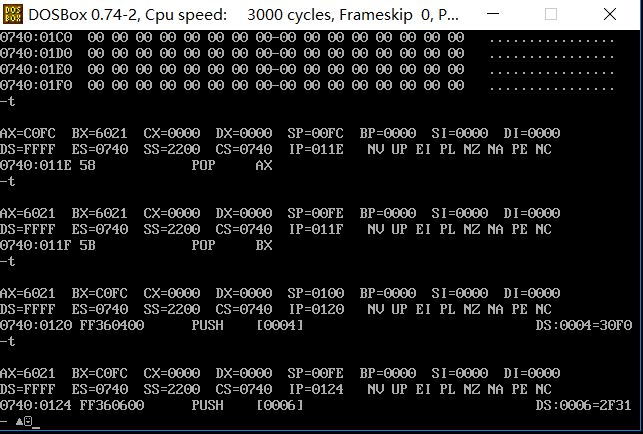
t指令 这是逐步执行我们的指令,然后我们就可以看里面的寄存器的具体情况了,当然还有每一步中的指令。这也是调试必用指令。
r指令 这是一个修改,查看cpu寄存器的一个指令,没有怎么使用过
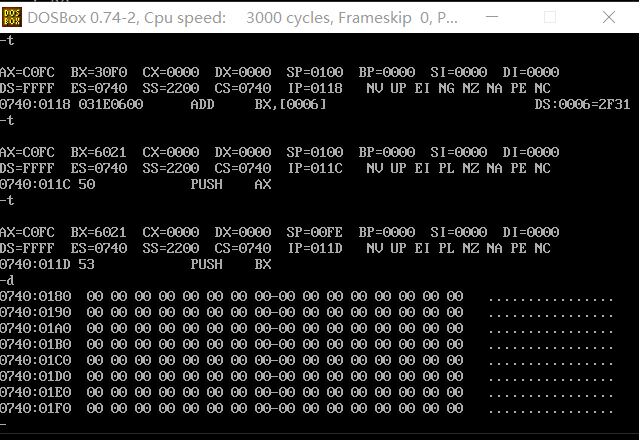
d指令 这是查看我们内存内容。
q指令 退出我们的debug,非常重要
t命令的使用:
d命令的使用:
有些讲的不是很详细,主要还是看我链接的博客。
n个人围成一个圈,每个人分别标注为1、2、…、n,要求从1号从1开始报数,报到k的人出圈,接着下一个人又从1开始报数,如此循环,直到只剩最后一个人时,该人即为胜利者。例如当n=10,k=4时,依次出列的人分别为4、8、2、7、3、10,9、1、6、5,则5号位置的人为胜利者。给定n个人,请你编程计算出最后胜利者标号数。(要求用单循环链表完成。)
1 | 第一行为人数n; |
1 | 输出最后胜利者的标号数。 |
1 | 10 |
1 | 5 |
由于是约瑟夫问题,这是一个超经典的一个题目,其中以前试过用数组做,不过好像要模拟其中的过程,所以其中的思维必须要清晰,而约瑟夫问题用单循环链表来做,逻辑会变得非常的简单,写下这篇博客,也是想记录链表的创建与删除,在约瑟夫问题上,链表真的起到了很大的作用。
1 | #include"iostream" |
设有一个背包可以放入的物品重量为S,现有n件物品,重量分别是w1,w2,w3,…Wn。
问能否从这n件物品中选择若干件放入背包中,使得放入的重量之和正好为S。
如果有满足条件的选择,则此背包有解,否则此背包问题无解
1 | 输入数据有多行,包括放入的物品重量为s,物品的件数n,以及每件物品的重量(输入数据均为正整数) |
对于每个测试实例,若满足条件则输出“YES”,若不满足则输出“NO“
1 | 20 5 |
1 | YES |
这是一个典型的动态规划问题,动态规划问题需要我们想的比较抽象一点,并且他常常又与递归结合,寻找最终的结果需要我们结合问题找到根本的执行步骤,例如此题,我们可以看作我们先找到目标的部分重量,然后再看剩下的目标重量是否能够通过我们已有的重量刚刚合适。W(n)=W(n-1)+Wi;其中Wi就是我们先找到的部分重量。
1 | #include<iostream> |
Libsvm是台湾大学林智仁(Chih-Jen Lin)博士等开发设计的一个操作简单、易于使用、快速有效的通用SVM 软件包,可以解决分类问题(包括C- SVC、n - SVC )、回归问题(包括e - SVR、n - SVR )以及分布估计(one-class-SVM )等问题,提供了线性、多项式、径向基和S形函数四种常用的核函数供选择,可以有效地解决多类问题、交叉验证选择参数、对不平衡样本加权、多类问题的概率
估计等。Libsvm是一个开源的软件包,需要者都可以免费的从作者的个人主页http://www.csie.ntu.edu.tw/~cjlin/ 处获得。不仅提供了Libsvm的C++语言的算法源代码,还提供了Python、Java、R、MATLAB、Perl、Ruby、LabVIEW以
及C#.net 等各种语言的接口,可以方便的在Windows 或UNIX 平台下使用,也便于科研工作者根据自己的需要进行改进(譬如设计使用符合自己特定问题需要的核函数等)。
按照Libsvm软件包所要求的格式准备数据集;
对数据进行简单的缩放操作;
考虑选用RBF 核函数2 K(x,y) e x y = -g - ;
采用交叉验证选择最佳参数C与g;
采用最佳参数C与g对整个训练集进行训练获取支持向量机模型;
利用获取的模型进行测试与预测。
由于libsvm实验中给出的数据并不是标准的libsvm数据模式,所以我们要对原本给出的测试数据和训练数据进行一个预处理,处理的方法我是才用的是excle的宏的使用,首先我们需要在网上下载一个叫FormatDataLibsvm.xls的一个表格。打开表格第一步一定要启用宏,这在excle的上方。
在excle的文件选项中打开我们需要预处理的数据文件,打开过程中设置我们数据格式,如下图,添加空格选项。

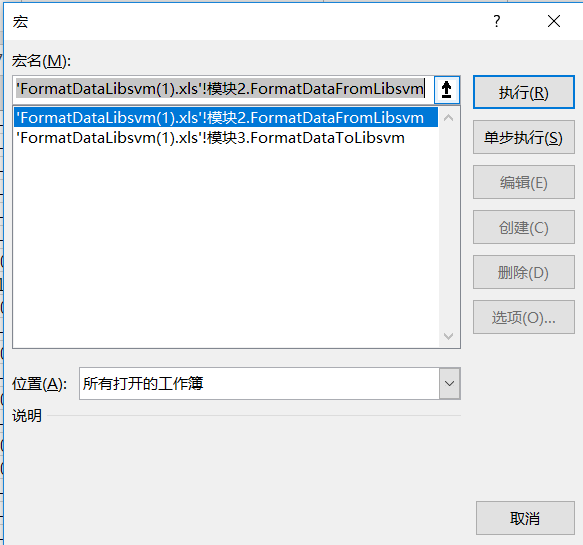
然后文件导入向导一直下一步,直到完成文件导入,然后在Excel上方搜索查看宏,并选择FormatDataToLibsvm的选项,点击执行,就能成功的改变数据的模式,每一列应该都是
从介绍中的个人主页中下载资源,其中有一个java文件就是我们要使用的东西
创建一个项目,在创建两个包,一个来包导入java文件中libsvm文件的内容,也可以复制粘贴到我们命名libsvm的这个包中,另一个包来写存java根目录下的四个java文件,之后我会把我的数据文件和主函数comMain(自己创建)都会放在这个包中进行操作。大概情况如下:

libsvm的使用主要是代码的调用,其中的数据文件中需要四个文本,一个测试数据test.txt,一个训练数据train.txt,一个模型数据moder_r .txt,一个输出数据out_r.txt,数据文件的路径可以随便放,但一定要知道路径,主函数代码如下:
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
String[] arg= {"G:\\java\\libsvm\\src\\service\\trainfile\\trainSVM.txt",
"G:\\java\\libsvm\\src\\service\\trainfile\\model_r.txt"};
String []parg= {"G:\\java\\libsvm\\src\\service\\trainfile\\testSVM.txt",
"G:\\java\\libsvm\\src\\service\\trainfile\\model_r.txt","G:\\java\\libsvm\\src\\service\\trainfile\\out_r.txt"};
System.out.println(".....SVM运行开始. . . . . .");
svm_train t=new svm_train();
svm_predict p=new svm_predict();
t.main(arg);
p.main(parg);
}
运行结果中各个字母的意义都可以查到,运行结果如下:

其中也许你的预测的准确率有可能没出来,可以采用不是对象调用,而是直接使用svm_predict的方法,我也不是很清楚当时就可以显示我的准确率了。
libsvm其实还需要计算出其中的最优参数c与g,这个好像要使用python的方法,当然libsvm也存在要对数据进行一个归一化的处理,好像是调用svm_scale的方法,java中的调用我没有看懂,所以只算了一个预测的准确率。推荐使用windows的方法来实现libsvm,操作简易并且不需要安软件。